Pada tahap ini kita telah belajar mengimplementasikan 2 model machine learning. Dataset yang telah kita gunakan memiliki atribut yang masih sangat sedikit sehingga proses pelatihan model yang kita bangun sebelumnya sangat cepat. Namun, dalam praktiknya, banyak masalah machine learning menggunakan dataset yang memiliki ribuan atau bahkan jutaan atribut, seperti pada dataset yang berisi informasi mengenai genetika manusia.
Dengan begitu banyaknya atribut, proses pelatihan akan menjadi lambat dan memakan waktu yang lama. Contoh lain pada kasus image recognition, di mana atribut dari image adalah jumlah pixel dari gambar tersebut. Jika sebuah gambar memiliki resolusi 28 x 28 pixel, maka gambar tersebut memiliki 784 atribut.
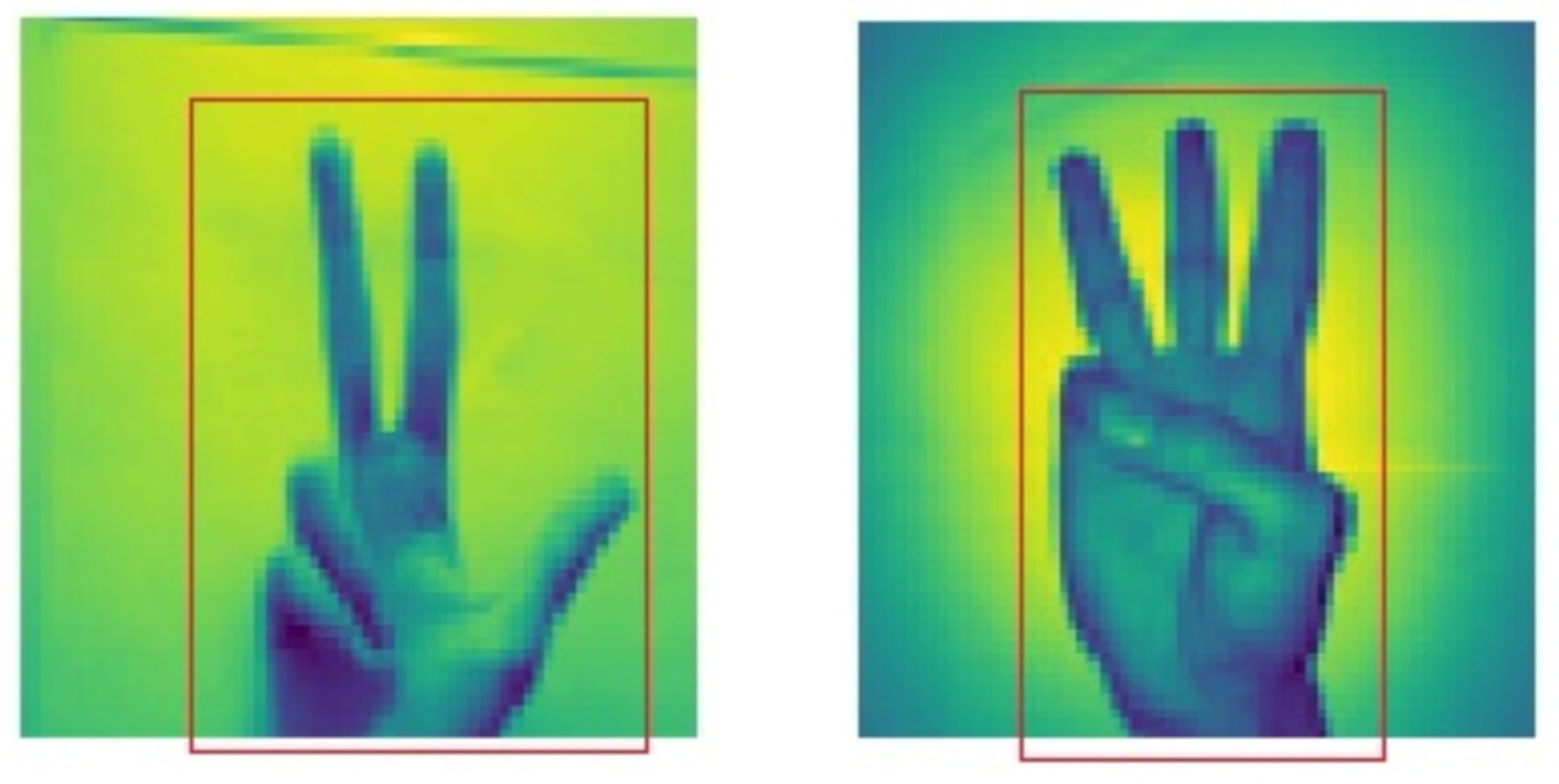
Pada 2 gambar di atas, setiap pixel adalah sebuah atribut. Hanya atribut yang berada di dalam kotak merah, yang berguna untuk dipakai dalam pelatihan model ML. Sebaliknya, atribut yang berada di luar kotak merah, tidak berguna dalam pelatihan model. Pengurangan dimensi pada kasus ini adalah dengan membuang pixel atau atribut yang berada di luar kotak merah. Bayangkan jika terdapat 10.000 gambar seperti di atas dalam sebuah dataset. Pengurangan dimensi akan mempercepat pelatihan model secara signifikan.
Ada beberapa teknik dalam pengurangan dimensi. Salah satu metode pengurangan dimensi yang terkenal adalah Principal Component Analysis atau sering disebut PCA.
Principal Component Analysis (PCA)
Secara sederhana, tujuan dari PCA adalah mengurangi jumlah atribut pada dataset tanpa mengurangi informasi. Contohnya pada sebuah dataset harga rumah. Pada PCA setiap atribut disebut sebagai principal component. Jika terdapat 10 atribut pada dataset, berarti terdapat 10 principal component. Pada gambar di bawah terdapat histogram dari 10 principal component dan variance dari setiap principal component.

PCA bekerja dengan menghitung variance dari tiap atribut. Variance adalah informasi yang dimiliki sebuah atribut. Misal pada dataset rumah, atribut jumlah kamar memiliki variance/atau informasi sebesar 92% dan warna rumah memiliki variance/informasi sebesar 4% tentang harga rumah terkait. Dari hasil perhitungan variance, atribut warna rumah dapat dibuang dari dataset karena tidak memiliki informasi yang cukup signifikan ketika kita ingin mempercepat pelatihan sebuah model.
LDA
Linear Discriminant Analysis atau analisis diskriminan linier adalah teknik statistika yang dipakai untuk reduksi dimensi. LDA bekerja dengan mencari kombinasi atribut terbaik yang dapat memisahkan kelas-kelas pada dataset. Kontras dengan PCA yang bekerja dengan mencari atribut komponen yang memiliki variance tertinggi.
Perbedaan mendasar lain yang membedakan LDA dan PCA adalah PCA merupakan teknik unsupervised, karena pada pengurangan dimensi, PCA tidak menghiraukan label yang terdapat pada dataset. Sedangkan LDA merupakan teknik supervised karena pada LDA memperhatikan bagaimana kelas-kelas pada data dapat dipisahkan dengan baik. Silakan kunjungi tautan berikut untuk membaca lebih lanjut mengenai LDA.
t-SNE
t-Distributed Stochastic Neighbor Embedding atau sering disebut t-SNE, adalah teknik lainnya dalam pengurangan dimensi. t-SNE mengurangi dimensi dengan menjaga sampel-sampel yang mirip agar berdekatan, dan sampel-sampel yang kurang mirip berjauhan.
t-SNE sering dipakai untuk visualisasi data yang memiliki dimensi besar dan dipakai luas dalam pemrosesan gambar, pemrosesan bahasa alami, data genomika, dan speech processing. Jika Anda tertarik melihat bagaimana implementasi dari t-SNE, Anda bisa mengunjungi tautan berikut
Komentar
Posting Komentar